on
Memory Management Unit and Instruction Decoding
This post continues the series about writing a snapshot fuzzer for iOS. We will take a look at the memory management unit and instruction decoding.
MMU layout
Many modern processors contain a Memory Management Unit (MMU). It is
responsible to translate virtual memory addresses to physical memory addresses.
When we took a core dump of a
process, the Mach-O header contained metadata
including the virtual addresses of the memory segments. These virtual addresses
indicated at which address the memory segments were loaded.
A major advantage of virtual addressing is process isolation. Every process can
see its own address space starting from 0x0 to the maximum address available for
the architecture. On 64 bit, this would be 0xffffffff_ffffffff. However, it
can’t access the address space of other processes without invoking a
syscall like process_vm_readv.
I iterated over several instances of the MMU until I arrived at a working one. It is still not perfect and can be improved, but for the time being, it’s good enough. The implemented MMU can translate from virtual addresses (VirtAddr) to emulator addresses (EmuAddr).
First MMU iteration - 1:1 Mapping of VirtAddr to EmuAddr
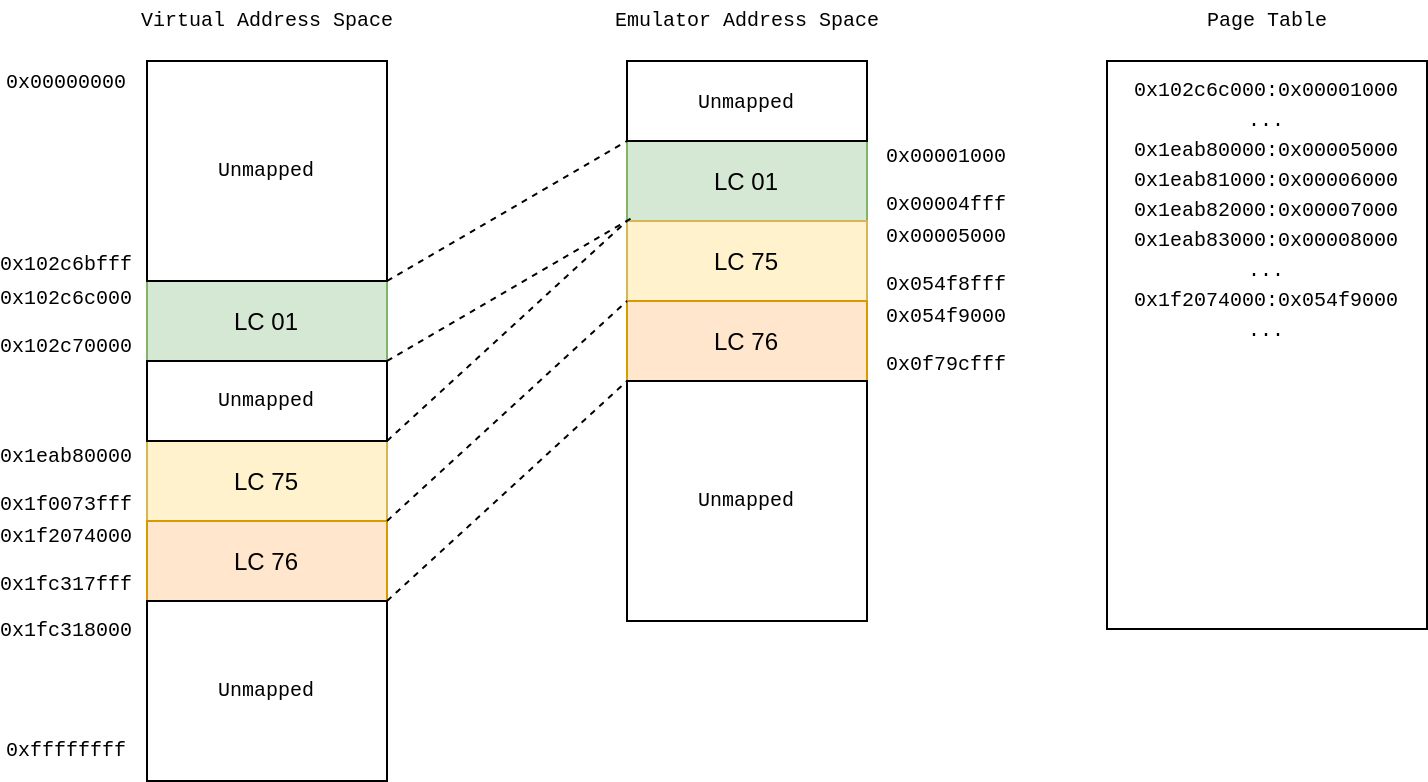
In the first iteration of the MMU, I simply allocated an array that was big enough to contain the whole mapped virtual address space of the dumped process. The maximum mapped segment that was dumped was at 0x1fc318000. The MMU’s memory contents could be accessed by indexing it with the VirtAddr. However, the array needed 8GiB and most of the values were just zeros. This is quite wasteful and to scale it to multiple cores, a lot of RAM would be needed.
jtool -l core_dump_add
LC 00: LC_THREAD Containing 1 thread states in 284 bytes
LC 01: LC_SEGMENT_64 Mem: 0x102c6c000-0x102c70000
LC 02: LC_SEGMENT_64 Mem: 0x102c70000-0x102c74000
...
LC 75: LC_SEGMENT_64 Mem: 0x1eab80000-0x1f0074000
LC 76: LC_SEGMENT_64 Mem: 0x1f2074000-0x1fc318000
Second MMU iteration - Remapping Segments
In the second iteration, I remapped the segments' virtual addresses to continuous memory in an array, eliminating the need to allocate space for all non-mapped segments. This introduced the need for a flat page table, which contained a mapping of page-aligned VirtAddrs to EmuAddrs. This reduced the memory usage to roughly 2GiB for all the memory contents which were dumped. However, the actual memory requirements are doubled because, for every byte of virtual memory, a bitmask is stored which contains the byte’s permissions. This means that one running emulator instance would need 4GiB of RAM which is still too much for my hardware.
The following diagram shows the mapping of the above core dump segments from virtual address space to emulator address space and its corresponding page table.
Third MMU iteration - Copying Only Dynamic Memory
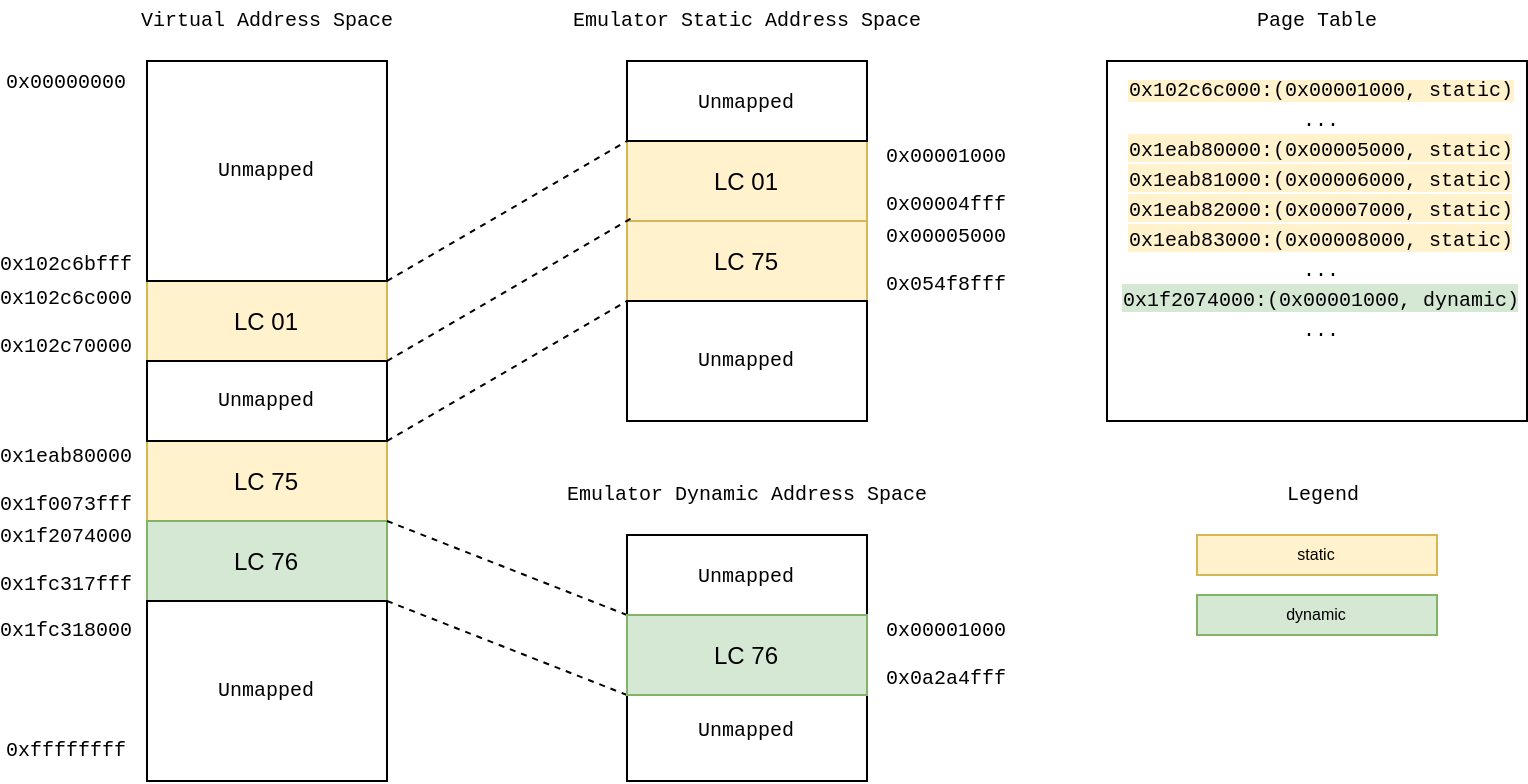
The current implementation contains two backing stores for the memory. It is split up into static/non-writable memory segments and dynamic/writable memory segments. Roughly 1750MiB of a 2GiB core dump are static memory segments. While loading the core dump, writable segments are stored in the dynamic memory backing store, whereas non-writable segments are stored in the static backing store. When the emulator forks, it only copies the dynamic memory. Only a reference to the static memory is passed to each VM. This leads to 500MiB of memory usage per VM in addition to the initial core dump and its permissions loaded to memory. At the moment, a page table stores the mapping of a VirtAddr to a tuple of (EmuAddr, MemType), where MemType can be either static or dynamic. This allows the VM to decide which backing store of memory it should use to retrieve the value at VirtAddr.
Fast resets
The MMU is designed to have fast resets. Therefore, the emulator tracks which memory is modified during the execution of a fuzz case. Only this modified dynamic memory must be reset which is often just a few (kilo)bytes depending on the fuzz case and not the complete 250MB of dynamic memory. To achieve this, a vector contains the index of modified blocks of memory. Furthermore, another vector contains a bitmap of which bytes were modified in the block of memory. The size of these dirty blocks can be varied to find the best value for each target. A larger size increases the amount a memcpy must copy, but it might decrease the amount of memcpy calls depending on the layout of the VM’s memory.
Byte-level Permissions
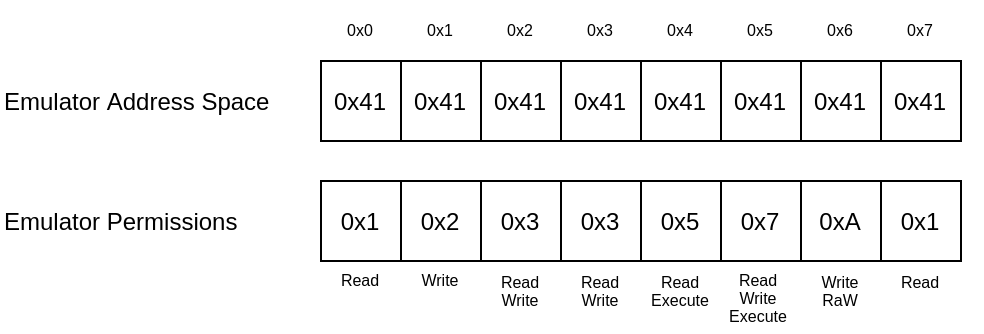
To catch uninitialized memory reads, out-of-bound reads and writes, as well as execution of data segments, the MMU features byte-level permissions. For every byte of memory, there is an additional byte containing a bitmask representing the byte’s permissions. Depending on the bit set, this can be read, write, execute, read after write (RaW) or a combination of these.
If the RaW bit is set, the memory is uninitialized. Should a read occur to a corresponding memory location, an uninitialized memory read can be easily observed. The following figure shows some possible values.
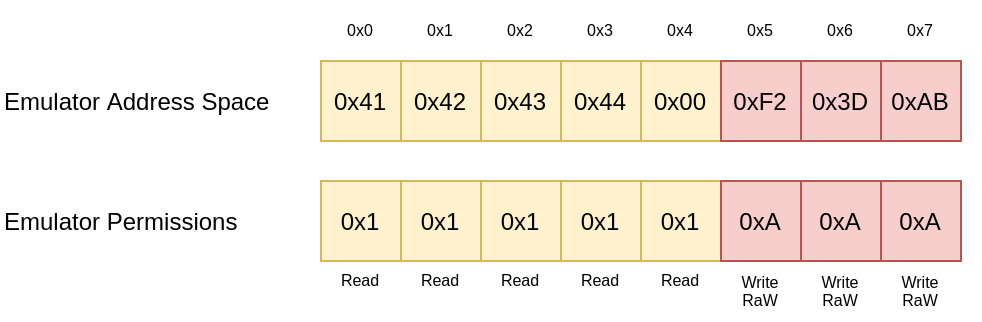
In the next example, memory can be read from address 0x0 to 0x4. If a program tries to read only a single byte over the out of bounds, it gets caught and an error is returned. If the program first writes to the memory at location 0x5 to 0x7, the RaW bit is cleared and the read bit is set. Then, it would also be possible to read from these memory locations.
The reset mechanism and the permission system are both influenced by gamozo’s RISC-V Emulator.
Future MMU iteration
The RAM usage is still relatively high for small fuzz cases because all memory segments are loaded into memory even if they don’t get used. A major improvement would be to only map memory segments or even pages that get actively used by the fuzz case. This can be achieved by only loading and copying memory if it is needed via Copy On Write. When the program counter is set and the first instruction should be executed, a page fault is triggered leading to mapping in the requested page containing the code to which the program counter points. If the first instruction is a load from memory, the first read to this memory page page faults first. Then, the memory requested memory is mapped in and can be read by the VM. This would reduce the RAM usage to a minimum of probably only a few KBytes or MBytes per VM.
Instruction Decoding
ARMv8 is a reduced instruction set computer (RISC) instruction set architecture (ISA). As most RISC ISA’s ARMv8 has fixed-length instructions that are 32bit long. Fetching and decoding these instructions is straightforward. The ARM Architecture Reference Manual describes the encoding of instructions in three steps. Starting with the main encoding table, instructions are split up into different groups identified by bits[25:28].
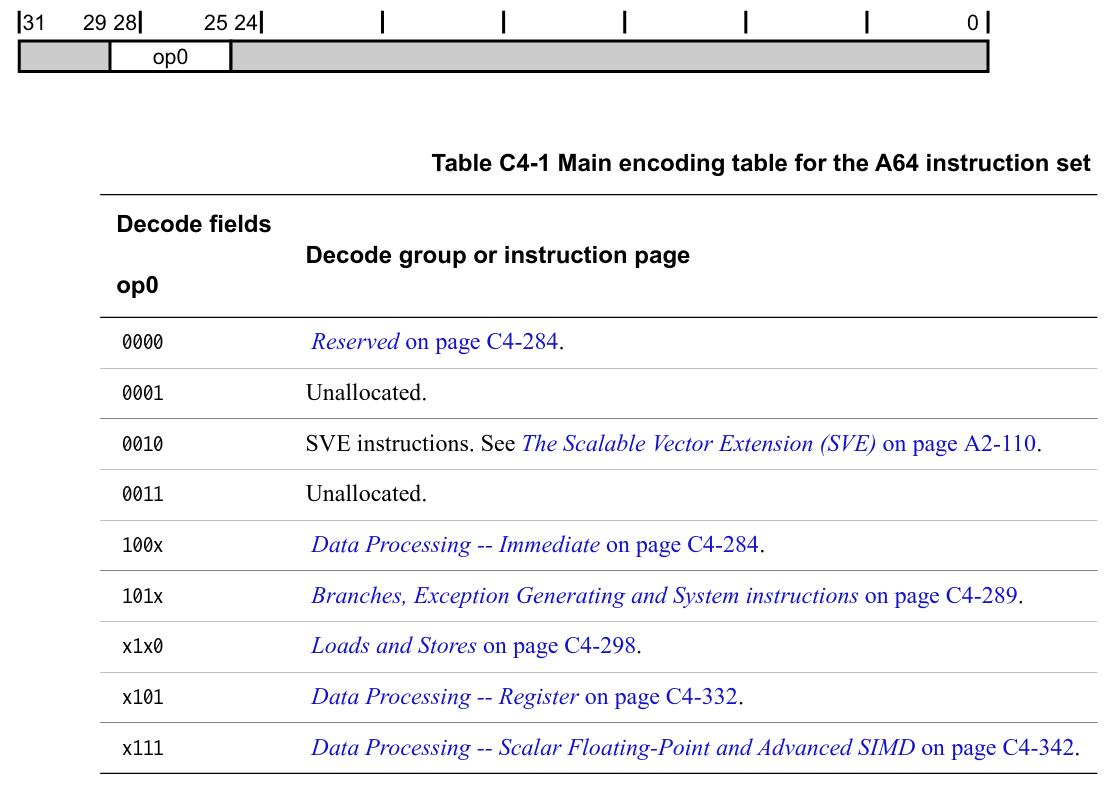
As an example, if the four bits match 1000 or 1001, then the group Data Processing – Immediate is selected. This group is then divided again into different subgroups by bits[23:25].
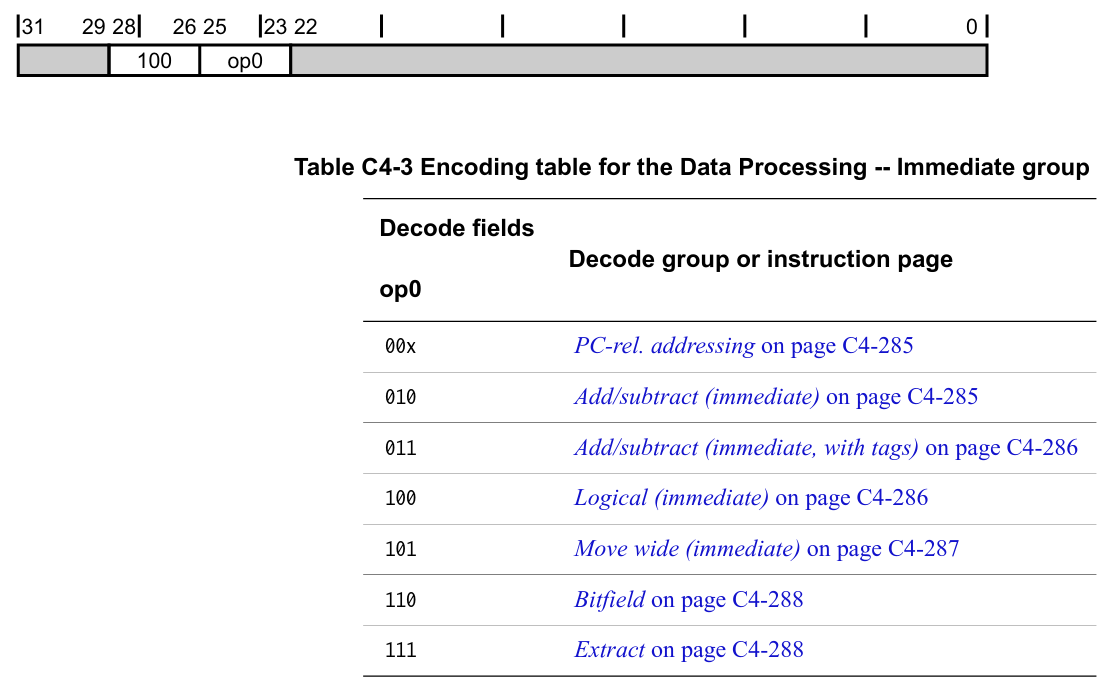
If the three bits are 010, we jump to Add/subtract (immediate) and finally can decode the parameters for the ADD(S)/SUB(S) instruction.
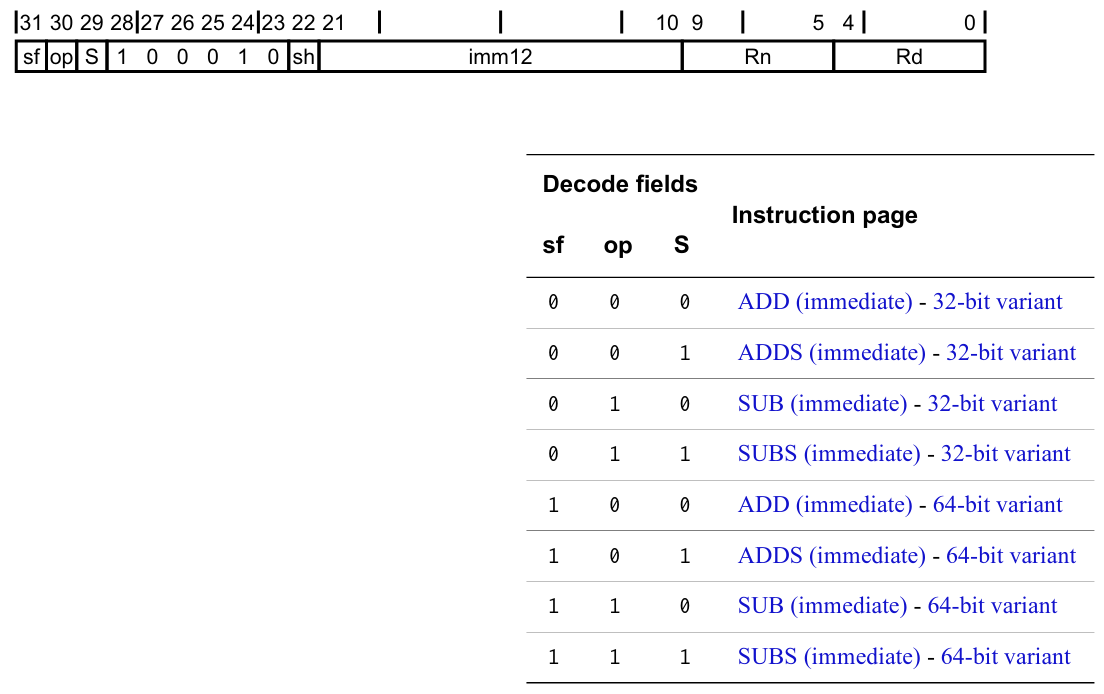
For the first few instructions I encountered in the core dump, I manually decoded them with a three-level match statement. However, decoding roughly 2000 different combinations of instructions and addressing modes is not really fun. Therefore, I looked around for various libraries I could use.
Capstone looked promising at first, especially because there are already Rust bindings. But these were incomplete and I started patching, however, the number of open issues and the problems I encountered while using it were quite disconcerting and that’s why I switched to Binary Ninja’s open-source ARM64 disassembler. A blog post details lots of background information on how the disassembler was more or less automatically created. yrp604 created nice Rust bindings for it. Both of them are well maintained and they are easy to work with.
I ran a few benchmarks by decoding instructions a million times on my laptop with an Intel Core i7-7500U processor. Capstone was the fastest with 708 ms, whereas Binary Ninja’s disassembler and my handwritten decoding routine were both at 914ms each.
So for a simple interpreter, the decoding speed matters a lot. This would already set a ceiling at around a million instructions per second per VM which is very slow. However, for a JIT the decoding speed doesn’t really matter. That’s what I’m working on currently.