on
Snapshot Fuzzing Basics
Snapshot Fuzzing
In our previous post, we looked at how to take a core dump. I quickly mentioned that the core dump will be used as a snapshot for fuzzing. This snapshot contains the complete memory state and the general-purpose registers of the program at a specific time of execution.
But why would you use snapshot fuzzing? First, we take a look at a hypothetical
scenario with a little bit of napkin math. Let’s say you would like to fuzz
Photoshop and chose the PSD format. If you have ever opened Photoshop, it
takes probably at least 5 seconds until it’s ready. Opening a .psd file
via the explorer takes another 2 seconds if you are quick. Loading the 5 MByte
file from an SSD takes another 1 ms, whereas the actual parsing takes only 0.1
ms - and you are only interested in the parsing. Closing Photoshop takes another
second. That would mean that 8.001 of
8.0011 seconds are wasted. That’s an efficiency of 0.0012%! So you waste
99.999% of the time you could actually spend fuzzing.
There are some improvements we could make. We could just not close and reopen Photoshop for each fuzz case which would save us a whopping 6 seconds. This brings our fuzzing efficiency to 6.001/6.0011 = 0.0016%. Still not great, but we’d lose a very important property - determinism. Determinism is “the property of having behavior determined only by initial state and input”1. It may be possible that a previously loaded PSD file changed a relevant state within Photoshop which impacts the control flow while parsing the following file. This may lead to non-reproducible behaviors.
Another way to improve the efficiency might be to open multiple .psd files at
once from the file explorer, therefore sharing the 2 seconds load time
over multiple files. That’s still not great if all we want to fuzz is
the PSD parser which takes only a fraction of the time. That’s where
snapshot fuzzing comes in handy.
Imagine you take a snapshot of Photoshop right after it has loaded a .psd file
in memory but before it is parsed. This skips the 5 second startup time and
2 second load time of the file explorer as well as the 1 ms load time from the
SSD. You can then directly start fuzzing the parser’s code. It’s even possible
to ditch Photoshop’s 1 second shutdown time by stopping execution right after
the parsing ends. When it stops, the memory can be restored to the state of the
snapshot and the .psd file can be mutated directly in memory before the next
round of execution continues. This means we can reduce the 8.0011 seconds to
just the 0.1 ms plus the time it takes to reset and mutate the emulator.
Not only does snapshot fuzzing increase the efficiency from 0.0012% to 99% if
you assume a reasonable overhead of 1% for resetting and mutating the input.
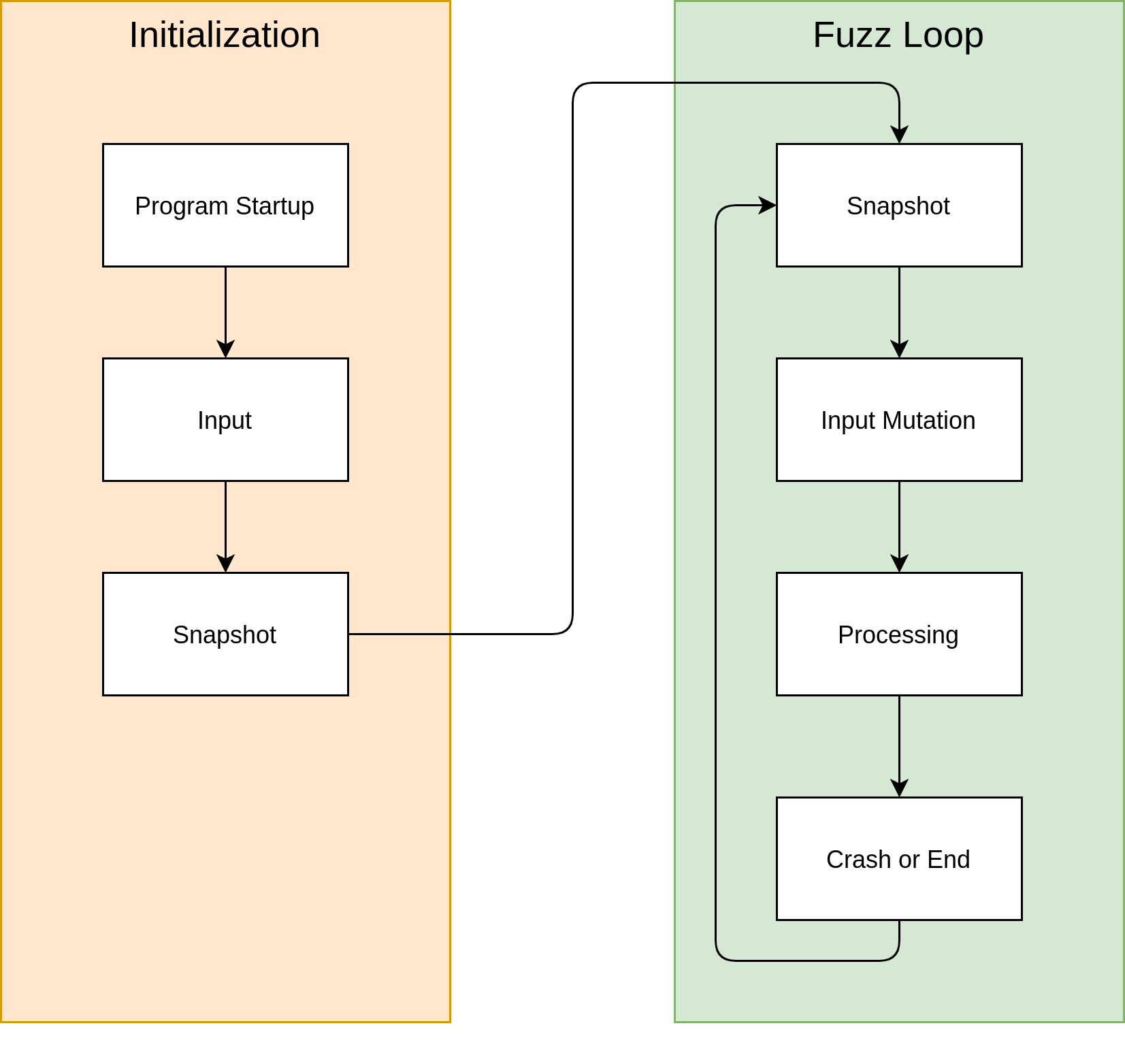
Basic Procedure of Snapshot Fuzzing
This flow chart shows a very high-level overview of snapshot fuzzing. We already attached a debugger and stopped the execution to take a snapshot in the last blog post. In the future, we will shift our focus on the fuzz loop that takes our snapshot, mutates the input in memory, and processes the input. If the execution reaches a defined stopping point or the program crashes, all state gets reset to the original snapshot and the loop starts again.
Snapshot Fuzzing Mechanisms
There exist at least three different mechanisms to perform snapshot fuzzing.
The first one that I chose for this project is emulation. Another possibility
is using a hypervisor like gamozo’s
chocolate_milk.
A third option is using live fuzzing which uses memory API calls like
process_vm_writev() to directly reset the memory of a process running on
a live system. You can find an example for live fuzzing on h0mbre’s
Fuzzing Like A Caveman 4
blog post.
Emulator for Fuzzing
An emulator is a program that adds an additional layer of abstraction between the host platform and the target platform2. The target platform can be a complete operating system or only a process. Furthermore, the target platform can have the same or different instruction set architecture than the host platform. For example, the mgba emulator allows running games designed and compiled for the Game Boy Advance on a Linux/Windows/macOS platform with an x86 or ARM instruction set architecture.
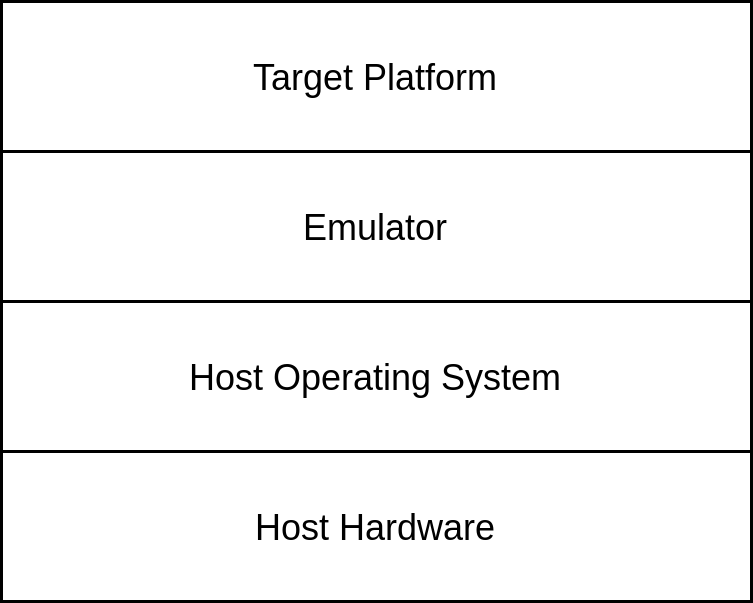
Emulator Design
There exist two main methods of emulation3. The first one is simple interpretation. An interpreter fetches, decodes and, emulates each individual target instruction which requires executing multiple host instructions and hence has relatively poor runtime performance characteristics. Secondly, dynamic binary translation translates each block of target instructions to a block of host instructions. This can lead to a much better runtime performance after the blocks are translated. The translation process is relatively slow. However, this only needs to be done once whereas the translated program literally executes millions of times while fuzzing.
Existing Work
There already exists some research using emulators for fuzzing in general or iOS specifically. For example, @zhyowei managed to boot the iOS kernel in QEMU. @JonathanAfek continued this research and was able to execute quite a few userspace processes including an SSH server and a bash shell. @lcamtuf and the team behind AFLplusplus brought fuzzing to the mainstream. AFL can fuzz binaries with QEMU as an emulator. @gamozolabs introduced writing emulators targeted specifically for fuzzing in his fuzz week.
Yet another emulator?
There are multiple reasons why I chose to write a custom emulator. Firstly, to fully understand each part of the system, I want to implement the complete emulator by myself. This gives me the ability to simply modify my emulator without having the uncertainty if these changes would impact a third-party emulator’s behavior. Furthermore, QEMU was not designed to execute a small amount of code over and over again and reset the complete state to the beginning efficiently. A traditional VM restore can take minutes. With my emulator, I can have a memory management unit that already implements features like AddressSanitizer to catch out-of-bounds accesses or use after frees.
Release of mach-dump
As promised in my last blog post, I release mach-dump which is a simple Rust library to load a Mach-O core dump generated by lldb. It parses all memory segments and thread states. These segments and thread states can then be easily loaded into an emulator like QEMU.
-
Virtual Machines - Jim Smith, Ravi Nair - p. 14 ↩︎